
前回の「【正月雑談】GoogleTrendsを使ってニューイヤー駅伝出場企業の検索動向を見た」で
Googleトレンドはあくまで相対評価のため、分母にするベンチマーク(今回で言えば「トヨタ自動車」)の検索ボリュームによって、他社のハネが強調されたり、逆に押しつぶされたりして見え方が激変する点には注意が必要です。
という補足事項を書きました。
実際にGoogleTrendsを使用した調査において比較対象を変更するとアウトプットがどのように変わるのかを調査してみました。
そもそもGoogleTrendsの比較対象による違いとは
そもそもGoogleTrendsの比較対象による違いとはなんなのか。
具体的に見てみるとこんな感じの違いです。
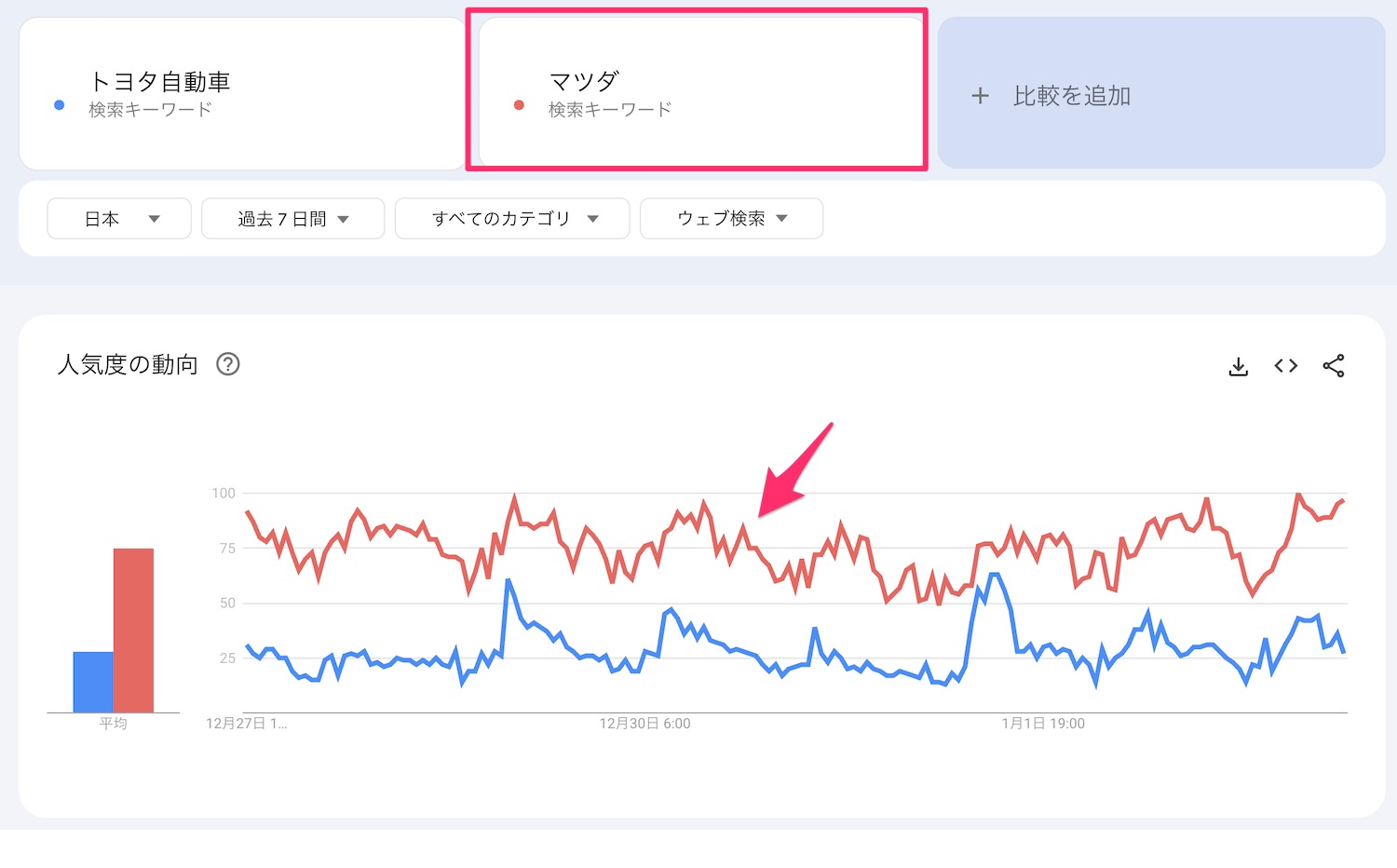
「トヨタ自動車」と比較した場合の「マツダ」の動き
「トヨタ自動車」の検索トレンドが相対的に小さいため「マツダ」の動きが大きく見えます。
「トヨタ」と比較した場合の「マツダ」の動き
では「トヨタ」と比較するとどうなるかというと、「トヨタ」の検索トレンドが相対的に大きいため、「マツダ」の動きが小さく見えてしまいます。
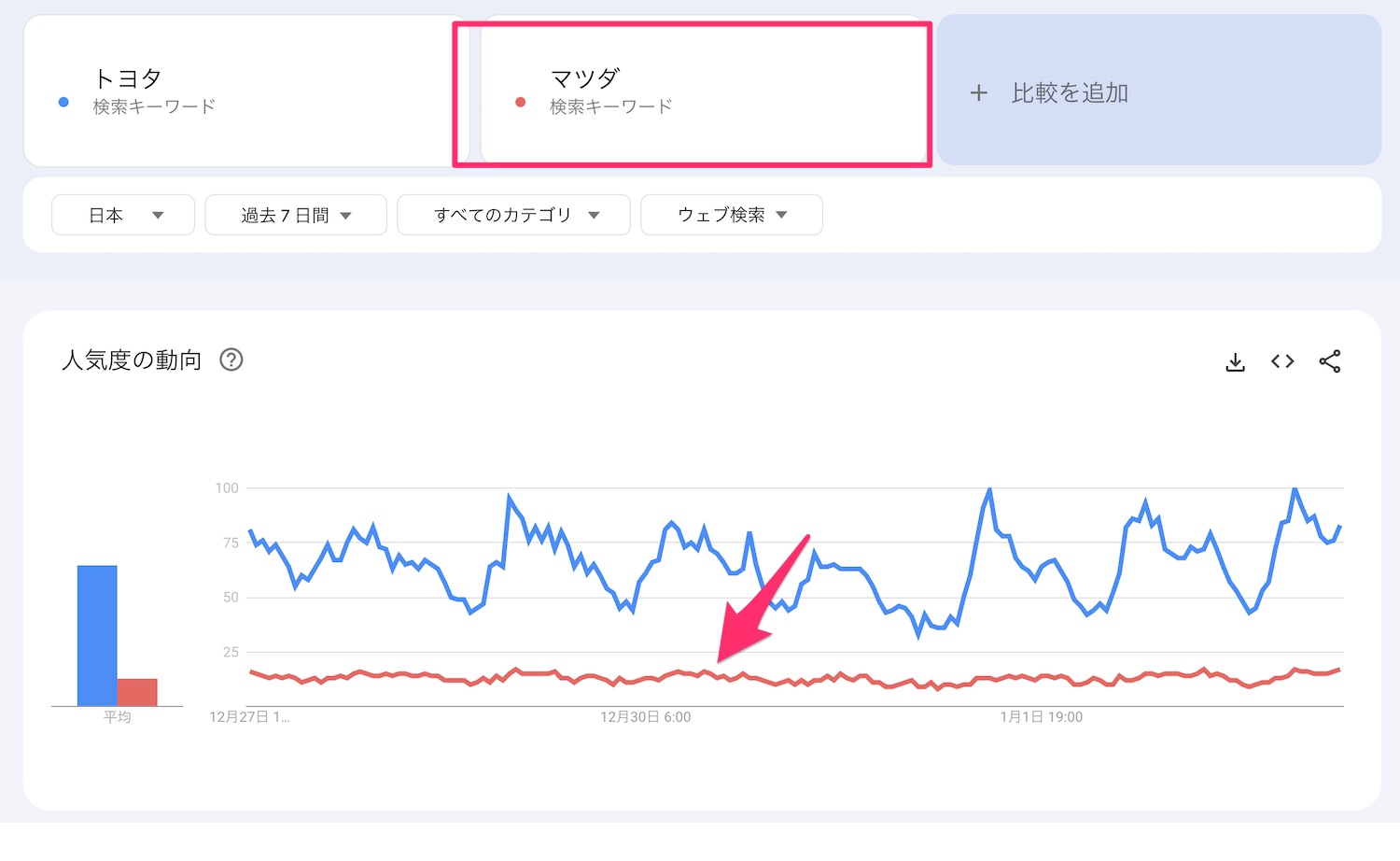
このように相対的な調査では比較対象に注意しないとデータの見え方が異なってしまうケースがあります。
ニューイヤー駅伝出場企業の検索動向の比較
前回の「【正月雑談】GoogleTrendsを使ってニューイヤー駅伝出場企業の検索動向を見た」では「トヨタ自動車」と比較して他の企業がどのような検索トレンドになっているかを調べたのですが、「トヨタ自動車」を「トヨタ」に変えるとどのように見え方が変化するのかを調べてみました。
使用したコード
基本的には前回と同じですが軸のキーワード(benchmark)を「トヨタ」に変更(赤箇所)しています。
あとM&Aを正式名称に、待機時間を変更(黄色マーカー)。
!pip install pytrendsimport pandas as pd
from pytrends.request import TrendReq
import time
# 1. 初期設定
pytrends = TrendReq(hl='ja-JP', tz=540)
# 基準にする会社(これに対する相対値で全社を算出します)
benchmark = "トヨタ"
# 40社のリスト(先ほどの文字起こしデータ)
kw_list = [
"GMO", "ロジスティード", "トヨタ自動車", "JR東日本", "サンベルクス",
"中国電力", "黒崎播磨", "Honda", "旭化成", "富士通",
"三菱重工", "安川電機", "SUBARU", "トヨタ紡織", "住友電工",
"大塚製薬", "西鉄", "愛知製鋼", "ヤクルト", "マツダ",
"プレス工業", "SGホールディングス", "ひらまつ病院", "愛三工業", "大阪ガス",
"コニカミノルタ", "トヨタ自動車九州", "クラフティア", "花王", "NDソフト",
"NTN", "大阪府警", "中電工", "トーエネック", "JFEスチール",
"セキノ興産", "中央発條", "YKK", "戸上電機製作所", "M&Aベストパートナーズ"
]
# 全データを格納するDataFrame
final_df = pd.DataFrame()
print("データ取得を開始します。40社あるため数分かかります...")
for kw in kw_list:
if kw == benchmark:
continue
# 基準と1社ずつ比較(ノイズを防ぐため「駅伝」を付与しても良いですが、まずは社名で)
search_keywords = [benchmark, kw]
try:
# 過去7日間(駅伝当日1/1を含む期間)を指定
pytrends.build_payload(search_keywords, timeframe='now 7-d', geo='JP')
df = pytrends.interest_over_time()
if not df.empty:
# 必要なカラムだけ抽出(isPartialは削除)
df = df.drop(columns=['isPartial'])
if final_df.empty:
final_df = df
else:
# 基準(benchmark)列以外の新しいキーワード列を結合
final_df = pd.concat([final_df, df[[kw]]], axis=1)
print(f"取得完了: {kw}")
# Googleにブロックされないよう少し待機
time.sleep(5)
except Exception as e:
print(f"エラー発生 ({kw}): {e}")
# 3. CSVとして保存(Colabの左メニューからダウンロード可能)
final_df.to_csv("newyear_ekiden_trends.csv", encoding="utf-8-sig")
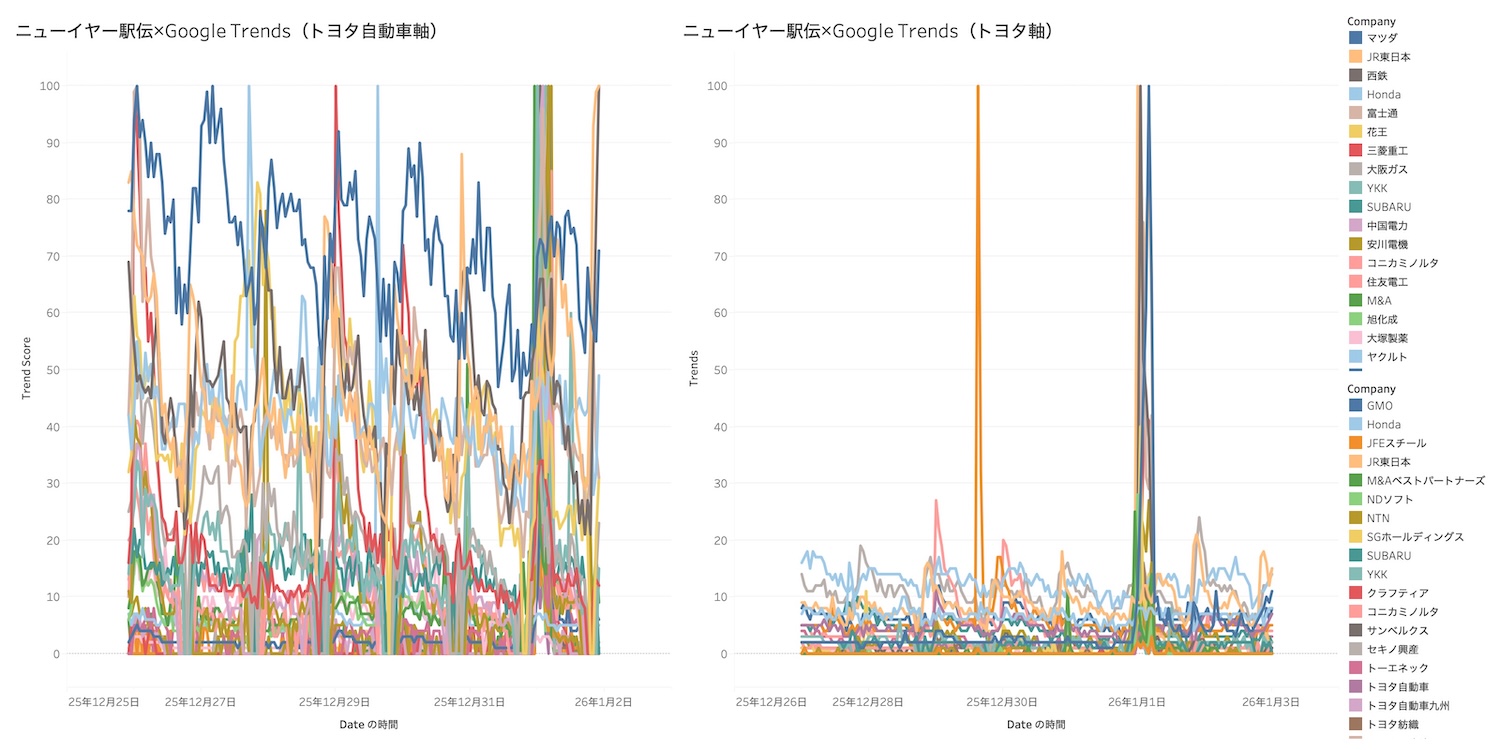
print("完了! 'newyear_ekiden_trends.csv' を作成しました。")「トヨタ自動車」軸(前回のもの)、右が「トヨタ」軸(今回のもの)でどう変化するか
左が「トヨタ自動車」軸(前回のもの)、右が「トヨタ」軸(今回のもの)。
全体像。
「トヨタ自動車」軸で(駅伝時に)変動の小さかった群。
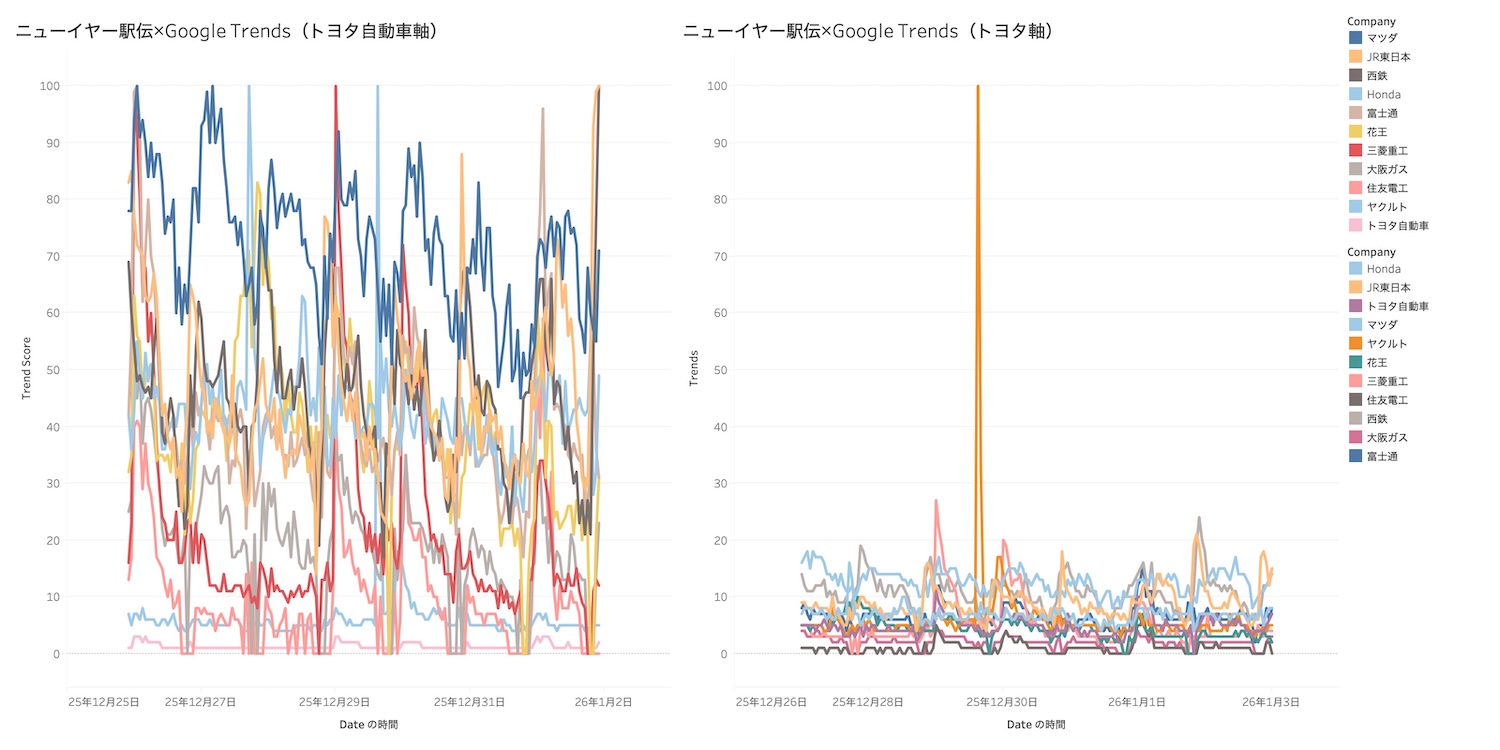
「トヨタ自動車」軸で(駅伝時に)変動の大きかった群。
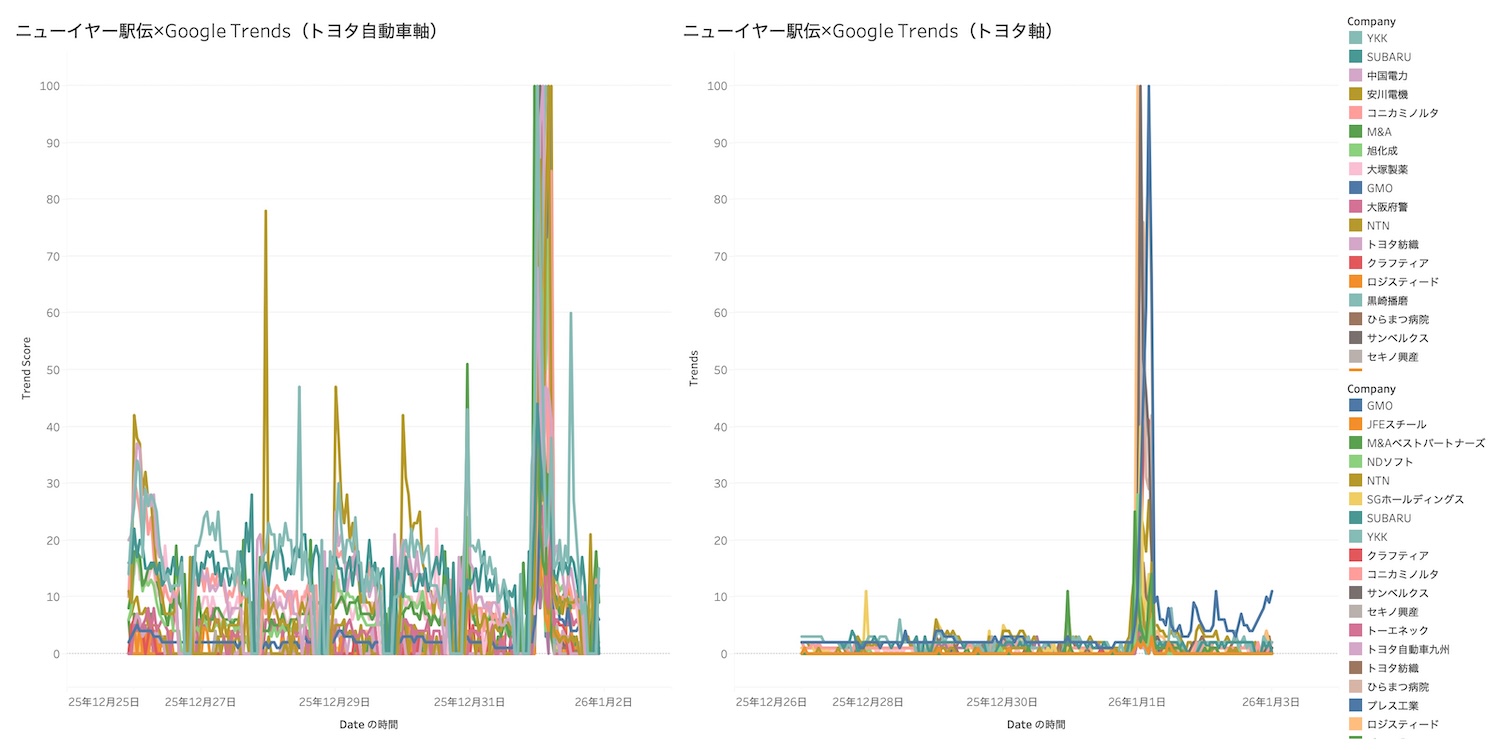
全然違いますね。
一言
GoogleTrendsを使って何かを比較する際に、比較対象によって傾向が変化する(結論も変化する可能性がある)ことがあるので注意したいという話でした。
「実際比較するとどう違うのかな」と思って描画しただけなので、他には言いたいことはないですw
意見をくださった@goshigoshi10さんありがとうございました。
〜完〜
ブログへのサポートのお願い(アマゾンギフト)
いつも「バカに毛が生えたブログ」をご愛読いただきありがとうございます。
現在、このブログは皆様のおかげで無料・広告なし(※)で運営しております。
※AdSenseはセンシティブ判定されてしまうため、広告を掲載できません。
ブログの継続とさらなる充実のためご支援をお願いします。
支援は一度限りのショット支援として、¥150から可能です。
いただいた支援は、以下のような形で活用させていただきます:
- サーバー費用やサイトの維持
- 新しいコンテンツの作成
- モチベーション
ご希望の方はスパチャ読みをいたしますので、その旨をお知らせください。
ご支援はより良いブログを提供するための力になります。
こちらのメールアドレスを送信先にしてください。
↓タップするとコピーされます



コメント